
中国乳腺癌标准数据库“大揭秘”:今天,来聊聊多模态数据“采、存、管、用“!
近十年来国家自然基金项目医学科学类中,多模态医学研究项目数量逐年增多,资助金额也逐渐增长。医学科学研究从关注“精准医学”向关注“高维度”医学大数据转变,需要纳入多样本、多维度的医疗数据来找寻更多的问题解决方法。
中国乳腺癌标准数据库实现了文本、影像、病理等数据的采集、治理与可视化,提供多模态数据从接入、利用到成果产出的全周期数据管理,为医学科研提供高质量数据支撑。
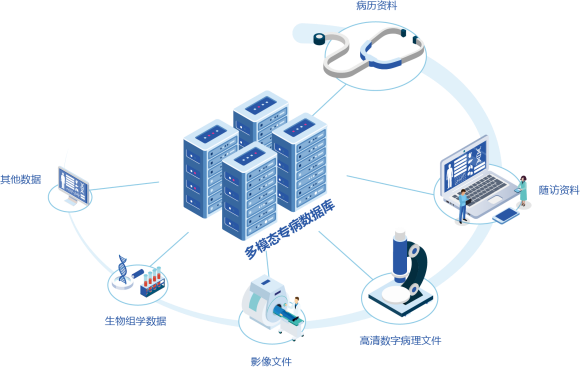
一、多模态数据采集
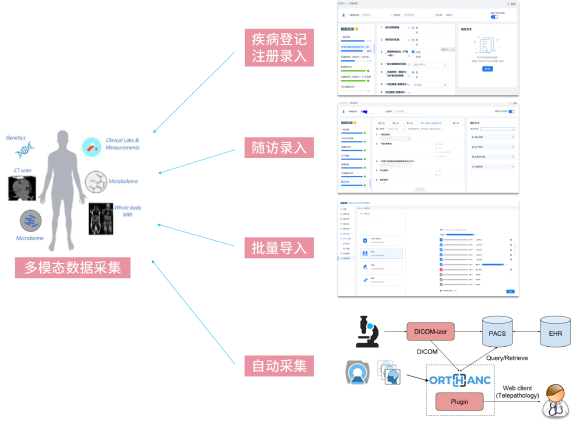
多模态数据采集包括疾病登记注册录入、随访录入、批量导入和自动采集。
(一)自动采集
各医院系统、数据标准不一致,除多源异构数据外,还可能存在错误、不完整数据。
中国乳腺癌标准数据库整合不同医院信息系统(HIS)、电子病历系统(EMR)、检验系统(LIS)、放射系统(PACS)、超声系统、心电系统等数据通道,通过自然语言处理技术(NLP)、数据仓库技术(ETL)、深度学习算法自动采集治理数据,将多源异构数据转化成结构化数据;检测不完整、格式错误或冗余数据,并智能校正。
(二)随访录入
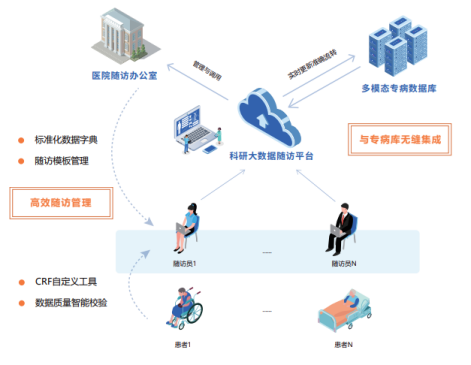
乳腺癌专病数据库与科研大数据随访平台无缝集成,利用CRF定义工具自动填充,患者生物学、体征量化、心理健康、行为追踪、环境测量等随访数据实时上传与分析,随时调用。
医务人员也可进行疾病登记注册录入和批量导入,根据需求对内容进行增/改/删。
二、多模态数据治理
数据治理是数据应用的基础。中国乳腺癌标准数据库遵循项目组事先制定的标准,对不标准的文本数据进行结构化数据映射,半结构化的文本数据进行NLP后结构化处理,对医学影像数据进行非结构化数据校正、特征提取,最终形成结构化、标准化、可利用、可共享的科研级数据。
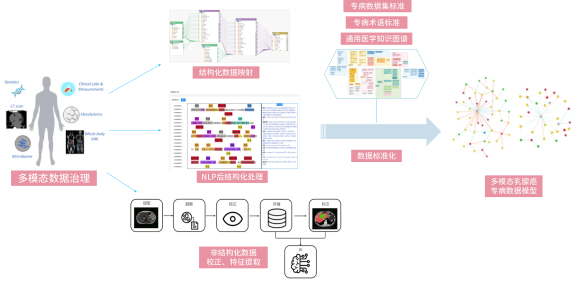
(一)结构化数据映射
结构化较好的文本数据,数据映射后结构化存储。
数据映射是从一个或多个数据库中将数据字段匹配到另一个数据库的过程,通过提取、转换和加载到目标数据库强化数据质量。借助ETL数据映射工具,可实现异构数据库之间的数据转换,将不同来源的数据定义相似数据点,弥合多系统间的差异,使数据精准的从数据库移出并匹配至目标数据库。
(二)NLP后结构化处理
后结构化处理即对半结构化文本型数据,用NLP技术提取出结构化信息,自动填入CRF表单中。
采集到的文本数据,医学团队利用NLP技术进行语义标注和训练,帮助计算机识别文本,实现机器学习、自动标注和算法调整,数据和术语标准化、归一化后预填于表格,经数据稽核后自动填入CRF表单,无缝对接乳腺癌专病数据库,实时管理与调用。
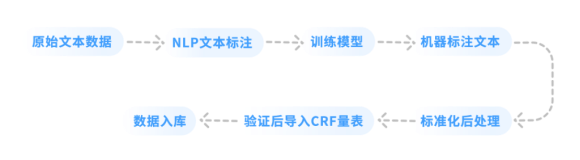
(三)非结构化数据校正、特征提取
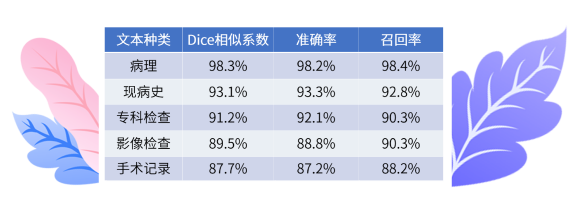
非结构化的医学影像、病理数据,以识别、分割和解析为核心任务。首先由临床医生进行实体和关系标注,标注量达到一定规模后,可利用训练出的模型反标注。在实体识别中,病理准确率可达98.3%,其他数据也均超87%。
在数据治理过程中,建立患者索引信息(EMPI),实现病患唯一索引。数据提取后,按患者ID/住院号/姓名/年龄等规则识别入库,串通患者治疗全过程。
标准化数据存储至多模态乳腺癌专病数据模型:临床文本数据通过后结构化、标准化存储到OMOP(通用数据模型),影像数据以DICOM格式存储,病理以SVS格式存储,基因数据以FASTQ格式存储,所有数据符合专病数据集标准、专病术语标准、通用医学知识图鉴等标准。
三、多模态数据可视化
多模态乳腺癌专病数据模型融合贯穿患者治疗全过程的数据,平台通过数据探索、数据明细钻取、影像序列视图、病理切片视图、全息数据视图、时间维度对比等方式,为管理员呈现全域数据资产。

(一)数据探索
首页以柱状图、饼图、折线图等方式可视化呈现患者数、影像、病理、基因等多模态数据,医务人员可直观看到多模态乳腺癌专病数据模型自动生成的分析报告,为科研灵感激发、课题设计提供参考。
(二)数据明细钻取
通过对影像数据的多层级数据明细钻取,医务人员可从庞大的影像数据中心快速定位至想要关注的数据,数秒锁定查找对象,提升检索效率。
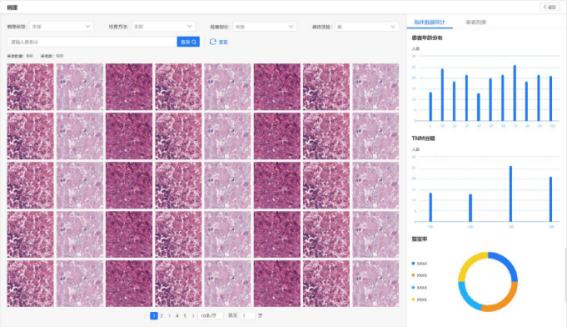
(三)影像序列视图、病理切片视图
医务人员可在影像序列视图、病理切片视图筛选数据,如类型、检查方法、部位、患者ID等,患者年龄分布、TNM分期、复发率等数据一目了然,实现对影像、病理图像快速调阅。
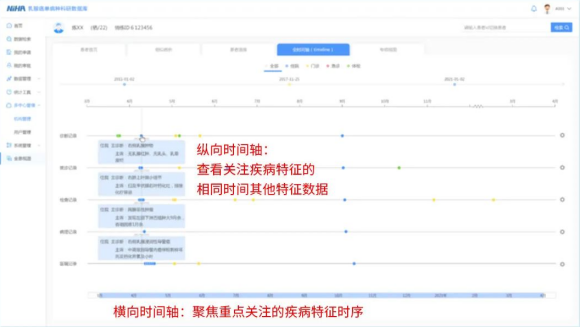
(四)全息数据视图、时间维度对比
全息视图360°展示患者全治疗周期,同一界面展示患者在每一个时间节点的诊断、用药、体征数据、检查、治疗、手术等数据,帮助医务人员快速聚焦患者信息,提高效率。
全量时间轴将患者的历次检查数据按时间顺序和类型陈列,辅助医务人员高效查阅患者诊疗信息,解读患者情况变化。
利用信息化手段开展临床科研创新是大势所趋。我们将陆续介绍中国乳腺癌标准数库中的更多功能,紧贴科研需求,为临床医生提供通用、完善的科研数据平台,助力乳腺癌单病种诊疗能力提升项目成果的不断涌现。